| ID | Radius | Texture | Perimeter | Area | Smoothness | Class |
|---|---|---|---|---|---|---|
| 926125 | 1.9275296 | 1.3485941 | 2.1001278 | 1.9667039 | 0.9627130 | M |
| 926424 | 2.1091388 | 0.7208383 | 2.0589739 | 2.3417954 | 1.0409262 | M |
| 926682 | 1.7033556 | 2.0833009 | 1.6145108 | 1.7223261 | 0.1023682 | M |
| 926954 | 0.7016669 | 2.0437755 | 0.6720844 | 0.5774446 | -0.8397450 | M |
| 927241 | 1.8367249 | 2.3344032 | 1.9807813 | 1.7336925 | 1.5244257 | M |
| 92751 | -1.8068114 | 1.2207179 | -1.8127934 | -1.3466044 | -3.1093489 | B |
Lecture 3
Introduction to Biostatistics
Something about me…
![]()
- I am an Assistant Professor of Teaching in the Department of Statistics at UBC.
- My graduate teaching is focused on the Master of Data Science, specifically in statistics.
- My undergraduate teaching has been mainly focused on scientific communication.
- My website: https://alexrod.netlify.app
- My email: alexrod@stat.ubc.ca
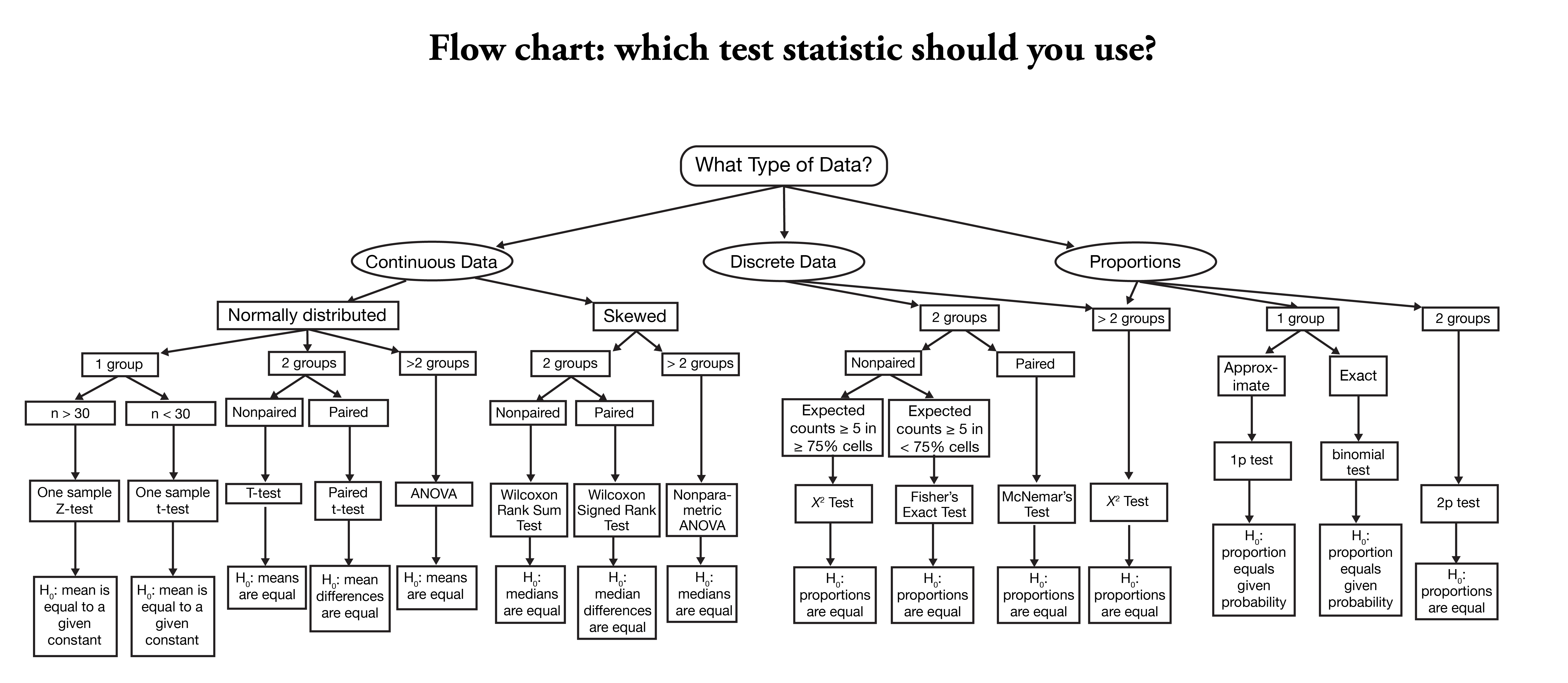
2. What is the question?
2.1. Descriptive
- One that seeks to summarize a characteristic of a set of data.
- No interpretation of any summarized result is needed.
- For instance, we can compute the average of any given variable in our dataset.
- If we do not interpret this average with respect to other data attributes, then our inquiry is merely descriptive.
Further descriptive examples
- What is the frequency of viral illnesses in a set of data collected from a group of individuals?
- How many people live in each US state?

2.2. Exploratory
- One in which you analyze the data to see if there are patterns, trends, or relationships between variables.
- This inquiry looks for patterns that would support proposing a hypothesis to test in a future study.
- Nevertheless, any exploratory insights would be limited to the data at hand.
Exploratory examples
- Do diets rich in certain foods have differing frequencies of viral illnesses in a set of data collected from a group of individuals?
- Does air pollution correlate with life expectancy in a set of data collected from groups of individuals from several regions in the United States?

Inferential examples
- Is eating at least 5 servings a day of fresh fruit and vegetables associated with fewer viral illnesses per year?
- Is the gestational length of first born babies the same as that of non-first borns?

2.4. Causal
- This inquiry asks about whether changing one factor will change another factor, on average, in a population.
- Sometimes, the underlying design of the data collection, by default, allows you to answer a causal question (e.g., randomized experiment or trial).

However…
- In other cases, the data collection does not allow the analysis to establish any causality.
- In particular, in observational studies, treatments are not controlled by design!
- Observed confounders can be included in the analysis but unobserved ones usually exist. Thus, causal effects cannot be naively established.

Causal examples
- Does eating at least 5 servings a day of fresh fruit and vegetables cause fewer viral illnesses per year?
- Does smoking cause cancer in BC elderly population?
Note: Designing an experiment where people are forced to smoke will be unethical! Observational data is often used in this case.

2.5. Mechanistic
- One that tries to explain the underlying mechanism of the observed patterns, trends, or relationship (i.e., how does it happen?).

Mechanistic examples
- How do changes in diet help to a reduction in the number of viral illnesses?
- How does airplane wing design changes air flow over a wing, leading to decreased drag?

3. So you know the type of question…

Another example
- If you have the question:
Is the gestational length of first born babies the same as that of non-first borns in Vancouver Island?
- And you identify that it is inferential. You could narrow down that some kind of statistical inference approach might help you answer that.

3.2. Then, again…
- You need to go a step deeper and look at the data that you have, and see which kind of statistical inference approach is the most suitable for your data.
4. Practice

4.6. A question for you!
- Write down one statistical question you are trying to answer with your research.
- Identify the type of question it is.

5. The statistical landscape in R
- Let us check the {tidyverse} collection of
Rpackages designed for data science.

Always start with a visualization
- The visualization should be related to your question!
- It should complement your statistical method(s).
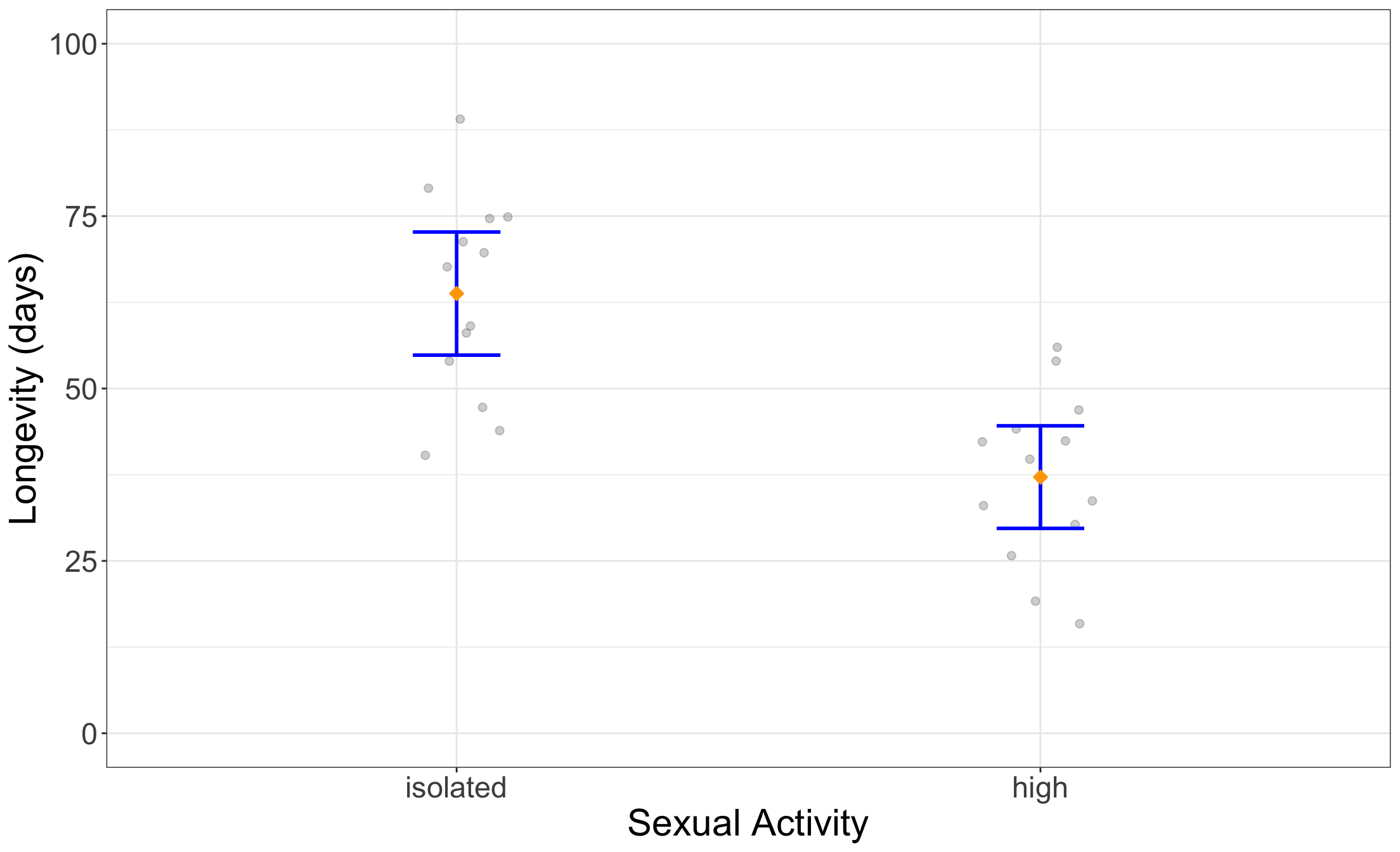
- We are interested in means – population means!
- So here, we should visualize our estimates of the population means, as well as our uncertainty about them!

Visualizing estimates and their uncertainty
- Calculate estimates and uncertainty.
- Visualize estimates and uncertainty, communicating as much about the underlying sample data as possible!
The plot
Questions?
All the source files of these slides are in this public GitHub repo: https://github.com/alexrod61/MEDI504-basic-biostats-2024.
Reference
- Wolberg,W.H., and Mangasarian,O.L. (1990). Multisurface method of pattern separation for medical diagnosis applied to breast cytology. In Proceedings of the National Academy of Sciences, 87, 9193-9196.
![]()